
Path: blob/main/examples/image_classification.ipynb
5906 views
Fine-tuning for Image Classification with 🤗 Transformers
This notebook shows how to fine-tune any pretrained Vision model for Image Classification on a custom dataset. The idea is to add a randomly initialized classification head on top of a pre-trained encoder, and fine-tune the model altogether on a labeled dataset.
ImageFolder
This notebook leverages the ImageFolder feature to easily run the notebook on a custom dataset (namely, EuroSAT in this tutorial). You can either load a Dataset from local folders or from local/remote files, like zip or tar.
Any model
This notebook is built to run on any image classification dataset with any vision model checkpoint from the Model Hub as long as that model has a version with a Image Classification head, such as:
in short, any model supported by AutoModelForImageClassification.
Data augmentation
This notebook leverages Torchvision's transforms for applying data augmentation - note that we do provide alternative notebooks which leverage other libraries, including:
Depending on the model and the GPU you are using, you might need to adjust the batch size to avoid out-of-memory errors. Set those two parameters, then the rest of the notebook should run smoothly.
In this notebook, we'll fine-tune from the https://huggingface.co/microsoft/swin-tiny-patch4-window7-224 checkpoint, but note that there are many, many more available on the hub.
Before we start, let's install the datasets, transformers and accelerate libraries.
If you're opening this notebook locally, make sure your environment has an install from the last version of those libraries.
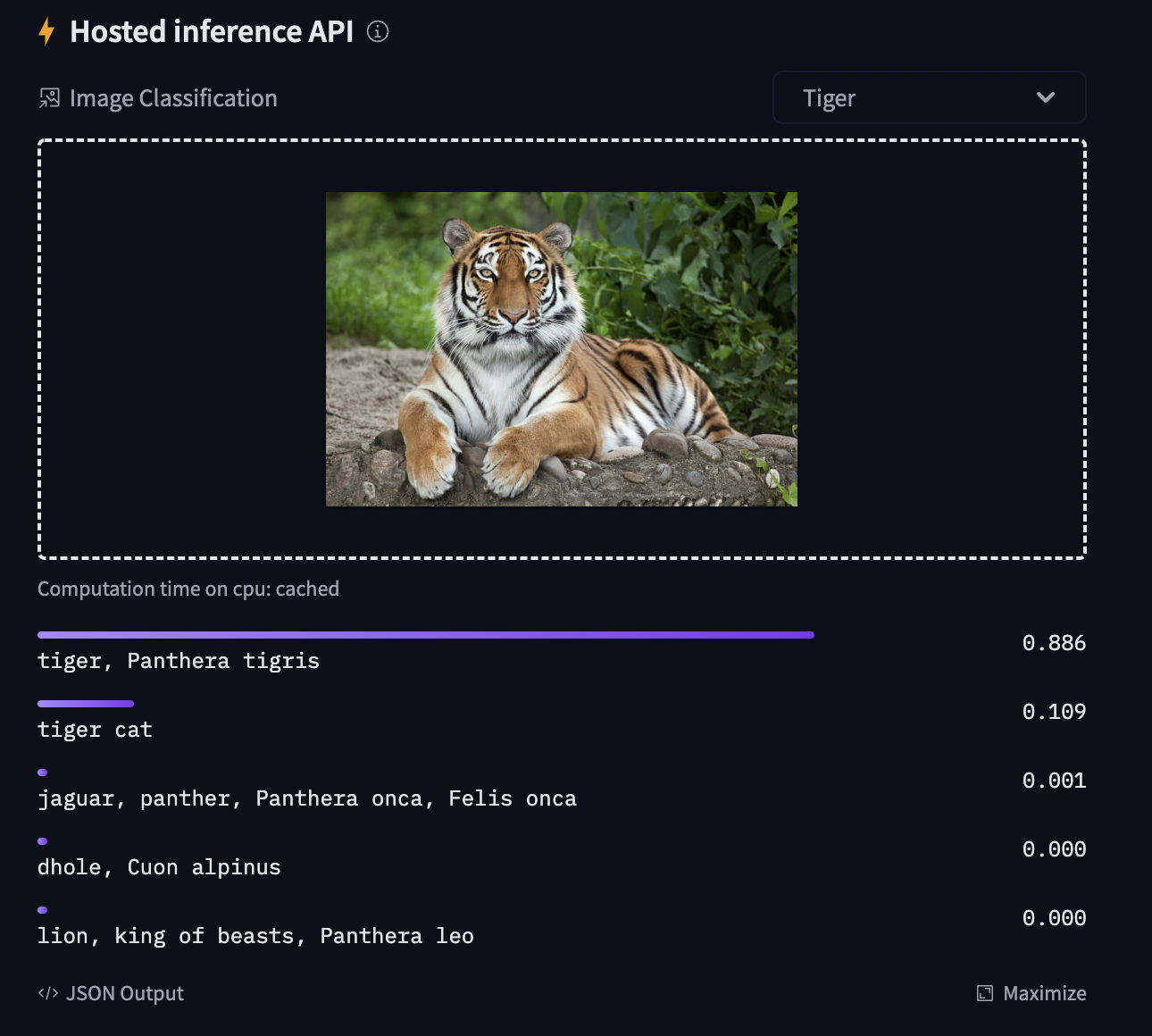
To be able to share your model with the community and generate results like the one shown in the picture below via the inference API, there are a few more steps to follow.
First you have to store your authentication token from the Hugging Face website (sign up here if you haven't already!) then execute the following cell and input your token:
Then you need to install Git-LFS to upload your model checkpoints:
We also quickly upload some telemetry - this tells us which examples and software versions are getting used so we know where to prioritize our maintenance efforts. We don't collect (or care about) any personally identifiable information, but if you'd prefer not to be counted, feel free to skip this step or delete this cell entirely.
Fine-tuning a model on an image classification task
In this notebook, we will see how to fine-tune one of the 🤗 Transformers vision models on an Image Classification dataset.
Given an image, the goal is to predict an appropriate class for it, like "tiger". The screenshot below is taken from a ViT fine-tuned on ImageNet-1k - try out the inference widget!
Loading the dataset
We will use the 🤗 Datasets library's ImageFolder feature to download our custom dataset into a DatasetDict.
In this case, the EuroSAT dataset is hosted remotely, so we provide the data_files argument. Alternatively, if you have local folders with images, you can load them using the data_dir argument.
Let us also load the Accuracy metric, which we'll use to evaluate our model both during and after training.
The dataset object itself is a DatasetDict, which contains one key per split (in this case, only "train" for a training split).
To access an actual element, you need to select a split first, then give an index:
Each example consists of an image and a corresponding label. We can also verify this by checking the features of the dataset:
The cool thing is that we can directly view the image (as the 'image' field is an Image feature), as follows:
Let's make it a little bigger as the images in the EuroSAT dataset are of low resolution (64x64 pixels):
Let's print the corresponding label:
As you can see, the label field is not an actual string label. By default the ClassLabel fields are encoded into integers for convenience:
Let's create an id2label dictionary to decode them back to strings and see what they are. The inverse label2id will be useful too, when we load the model later.
Preprocessing the data
Before we can feed these images to our model, we need to preprocess them.
Preprocessing images typically comes down to (1) resizing them to a particular size (2) normalizing the color channels (R,G,B) using a mean and standard deviation. These are referred to as image transformations.
In addition, one typically performs what is called data augmentation during training (like random cropping and flipping) to make the model more robust and achieve higher accuracy. Data augmentation is also a great technique to increase the size of the training data.
We will use torchvision.transforms for the image transformations/data augmentation in this tutorial, but note that one can use any other package (like albumentations, imgaug, Kornia etc.).
To make sure we (1) resize to the appropriate size (2) use the appropriate image mean and standard deviation for the model architecture we are going to use, we instantiate what is called an image processor with the AutoImageProcessor.from_pretrained method.
This image processor is a minimal preprocessor that can be used to prepare images for inference.
The Datasets library is made for processing data very easily. We can write custom functions, which can then be applied on an entire dataset (either using .map() or .set_transform()).
Here we define 2 separate functions, one for training (which includes data augmentation) and one for validation (which only includes resizing, center cropping and normalizing).
Next, we can preprocess our dataset by applying these functions. We will use the set_transform functionality, which allows to apply the functions above on-the-fly (meaning that they will only be applied when the images are loaded in RAM).
Let's access an element to see that we've added a "pixel_values" feature:
Training the model
Now that our data is ready, we can download the pretrained model and fine-tune it. For classification we use the AutoModelForImageClassification class. Calling the from_pretrained method on it will download and cache the weights for us. As the label ids and the number of labels are dataset dependent, we pass label2id, and id2label alongside the model_checkpoint here. This will make sure a custom classification head will be created (with a custom number of output neurons).
NOTE: in case you're planning to fine-tune an already fine-tuned checkpoint, like facebook/convnext-tiny-224 (which has already been fine-tuned on ImageNet-1k), then you need to provide the additional argument ignore_mismatched_sizes=True to the from_pretrained method. This will make sure the output head (with 1000 output neurons) is thrown away and replaced by a new, randomly initialized classification head that includes a custom number of output neurons. You don't need to specify this argument in case the pre-trained model doesn't include a head.
The warning is telling us we are throwing away some weights (the weights and bias of the classifier layer) and randomly initializing some other (the weights and bias of a new classifier layer). This is expected in this case, because we are adding a new head for which we don't have pretrained weights, so the library warns us we should fine-tune this model before using it for inference, which is exactly what we are going to do.
To instantiate a Trainer, we will need to define the training configuration and the evaluation metric. The most important is the TrainingArguments, which is a class that contains all the attributes to customize the training. It requires one folder name, which will be used to save the checkpoints of the model.
Most of the training arguments are pretty self-explanatory, but one that is quite important here is remove_unused_columns=False. This one will drop any features not used by the model's call function. By default it's True because usually it's ideal to drop unused feature columns, making it easier to unpack inputs into the model's call function. But, in our case, we need the unused features ('image' in particular) in order to create 'pixel_values'.
Here we set the evaluation to be done at the end of each epoch, tweak the learning rate, use the batch_size defined at the top of the notebook and customize the number of epochs for training, as well as the weight decay. Since the best model might not be the one at the end of training, we ask the Trainer to load the best model it saved (according to metric_name) at the end of training.
The last argument push_to_hub allows the Trainer to push the model to the Hub regularly during training. Remove it if you didn't follow the installation steps at the top of the notebook. If you want to save your model locally with a name that is different from the name of the repository, or if you want to push your model under an organization and not your name space, use the hub_model_id argument to set the repo name (it needs to be the full name, including your namespace: for instance "nielsr/vit-finetuned-cifar10" or "huggingface/nielsr/vit-finetuned-cifar10").
Next, we need to define a function for how to compute the metrics from the predictions, which will just use the metric we loaded earlier. The only preprocessing we have to do is to take the argmax of our predicted logits:
We also define a collate_fn, which will be used to batch examples together. Each batch consists of 2 keys, namely pixel_values and labels.
Then we just need to pass all of this along with our datasets to the Trainer:
You might wonder why we pass along the image_processor as a tokenizer when we already preprocessed our data. This is only to make sure the image processor configuration file (stored as JSON) will also be uploaded to the repo on the hub.
Now we can finetune our model by calling the train method:
We can check with the evaluate method that our Trainer did reload the best model properly (if it was not the last one):
You can now upload the result of the training to the Hub, just execute this instruction (note that the Trainer will automatically create a model card as well as Tensorboard logs - see the "Training metrics" tab - amazing isn't it?):
You can now share this model with all your friends, family, favorite pets: they can all load it with the identifier "your-username/the-name-you-picked" so for instance:
Inference
Let's say you have a new image, on which you'd like to make a prediction. Let's load a satellite image of a forest (that's not part of the EuroSAT dataset), and see how the model does.
We'll load the image processor and model from the hub (here, we use the Auto Classes, which will make sure the appropriate classes will be loaded automatically based on the config.json and preprocessor_config.json files of the repo on the hub):
Looks like our model got it correct!
Pipeline API
An alternative way to quickly perform inference with any model on the hub is by leveraging the Pipeline API, which abstracts away all the steps we did manually above for us. It will perform the preprocessing, forward pass and postprocessing all in a single object.
Let's showcase this for our trained model:
As we can see, it does not only show the class label with the highest probability, but does return the top 5 labels, with their corresponding scores. Note that the pipelines also work with local models and mage processors: