"""
Title: Low-light image enhancement using MIRNet
Author: [Soumik Rakshit](http://github.com/soumik12345)
Date created: 2021/09/11
Last modified: 2023/07/15
Description: Implementing the MIRNet architecture for low-light image enhancement.
Accelerator: GPU
Converted to Keras 3 by: [Soumik Rakshit](http://github.com/soumik12345)
"""
"""
## Introduction
With the goal of recovering high-quality image content from its degraded version, image
restoration enjoys numerous applications, such as in
photography, security, medical imaging, and remote sensing. In this example, we implement the
**MIRNet** model for low-light image enhancement, a fully-convolutional architecture that
learns an enriched set of
features that combines contextual information from multiple scales, while
simultaneously preserving the high-resolution spatial details.
### References:
- [Learning Enriched Features for Real Image Restoration and Enhancement](https://arxiv.org/abs/2003.06792)
- [The Retinex Theory of Color Vision](http://www.cnbc.cmu.edu/~tai/cp_papers/E.Land_Retinex_Theory_ScientifcAmerican.pdf)
- [Two deterministic half-quadratic regularization algorithms for computed imaging](https://ieeexplore.ieee.org/document/413553)
"""
"""
## Downloading LOLDataset
The **LoL Dataset** has been created for low-light image enhancement.
It provides 485 images for training and 15 for testing. Each image pair in the dataset
consists of a low-light input image and its corresponding well-exposed reference image.
"""
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import random
import numpy as np
from glob import glob
from PIL import Image, ImageOps
import matplotlib.pyplot as plt
import keras
from keras import layers
import tensorflow as tf
"""shell
wget https://huggingface.co/datasets/geekyrakshit/LoL-Dataset/resolve/main/lol_dataset.zip
unzip -q lol_dataset.zip && rm lol_dataset.zip
"""
"""
## Creating a TensorFlow Dataset
We use 300 image pairs from the LoL Dataset's training set for training,
and we use the remaining 185 image pairs for validation.
We generate random crops of size `128 x 128` from the image pairs to be
used for both training and validation.
"""
random.seed(10)
IMAGE_SIZE = 128
BATCH_SIZE = 4
MAX_TRAIN_IMAGES = 300
def read_image(image_path):
image = tf.io.read_file(image_path)
image = tf.image.decode_png(image, channels=3)
image.set_shape([None, None, 3])
image = tf.cast(image, dtype=tf.float32) / 255.0
return image
def random_crop(low_image, enhanced_image):
low_image_shape = tf.shape(low_image)[:2]
low_w = tf.random.uniform(
shape=(), maxval=low_image_shape[1] - IMAGE_SIZE + 1, dtype=tf.int32
)
low_h = tf.random.uniform(
shape=(), maxval=low_image_shape[0] - IMAGE_SIZE + 1, dtype=tf.int32
)
low_image_cropped = low_image[
low_h : low_h + IMAGE_SIZE, low_w : low_w + IMAGE_SIZE
]
enhanced_image_cropped = enhanced_image[
low_h : low_h + IMAGE_SIZE, low_w : low_w + IMAGE_SIZE
]
low_image_cropped.set_shape([IMAGE_SIZE, IMAGE_SIZE, 3])
enhanced_image_cropped.set_shape([IMAGE_SIZE, IMAGE_SIZE, 3])
return low_image_cropped, enhanced_image_cropped
def load_data(low_light_image_path, enhanced_image_path):
low_light_image = read_image(low_light_image_path)
enhanced_image = read_image(enhanced_image_path)
low_light_image, enhanced_image = random_crop(low_light_image, enhanced_image)
return low_light_image, enhanced_image
def get_dataset(low_light_images, enhanced_images):
dataset = tf.data.Dataset.from_tensor_slices((low_light_images, enhanced_images))
dataset = dataset.map(load_data, num_parallel_calls=tf.data.AUTOTUNE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
return dataset
train_low_light_images = sorted(glob("./lol_dataset/our485/low/*"))[:MAX_TRAIN_IMAGES]
train_enhanced_images = sorted(glob("./lol_dataset/our485/high/*"))[:MAX_TRAIN_IMAGES]
val_low_light_images = sorted(glob("./lol_dataset/our485/low/*"))[MAX_TRAIN_IMAGES:]
val_enhanced_images = sorted(glob("./lol_dataset/our485/high/*"))[MAX_TRAIN_IMAGES:]
test_low_light_images = sorted(glob("./lol_dataset/eval15/low/*"))
test_enhanced_images = sorted(glob("./lol_dataset/eval15/high/*"))
train_dataset = get_dataset(train_low_light_images, train_enhanced_images)
val_dataset = get_dataset(val_low_light_images, val_enhanced_images)
print("Train Dataset:", train_dataset.element_spec)
print("Val Dataset:", val_dataset.element_spec)
"""
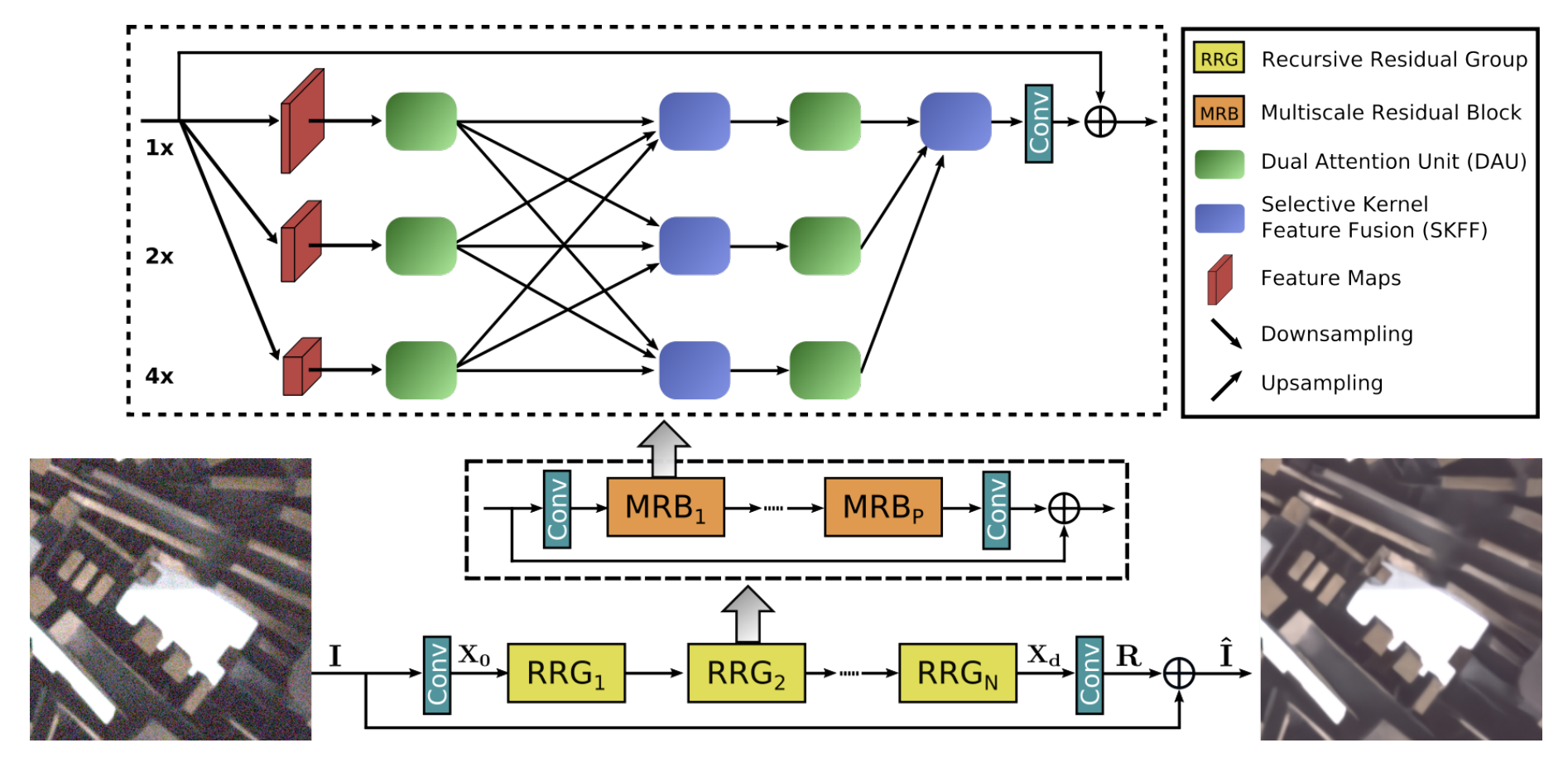
## MIRNet Model
Here are the main features of the MIRNet model:
- A feature extraction model that computes a complementary set of features across multiple
spatial scales, while maintaining the original high-resolution features to preserve
precise spatial details.
- A regularly repeated mechanism for information exchange, where the features across
multi-resolution branches are progressively fused together for improved representation
learning.
- A new approach to fuse multi-scale features using a selective kernel network
that dynamically combines variable receptive fields and faithfully preserves
the original feature information at each spatial resolution.
- A recursive residual design that progressively breaks down the input signal
in order to simplify the overall learning process, and allows the construction
of very deep networks.
"""
"""
### Selective Kernel Feature Fusion
The Selective Kernel Feature Fusion or SKFF module performs dynamic adjustment of
receptive fields via two operations: **Fuse** and **Select**. The Fuse operator generates
global feature descriptors by combining the information from multi-resolution streams.
The Select operator uses these descriptors to recalibrate the feature maps (of different
streams) followed by their aggregation.
**Fuse**: The SKFF receives inputs from three parallel convolution streams carrying
different scales of information. We first combine these multi-scale features using an
element-wise sum, on which we apply Global Average Pooling (GAP) across the spatial
dimension. Next, we apply a channel- downscaling convolution layer to generate a compact
feature representation which passes through three parallel channel-upscaling convolution
layers (one for each resolution stream) and provides us with three feature descriptors.
**Select**: This operator applies the softmax function to the feature descriptors to
obtain the corresponding activations that are used to adaptively recalibrate multi-scale
feature maps. The aggregated features are defined as the sum of product of the corresponding
multi-scale feature and the feature descriptor.

"""
def selective_kernel_feature_fusion(
multi_scale_feature_1, multi_scale_feature_2, multi_scale_feature_3
):
channels = list(multi_scale_feature_1.shape)[-1]
combined_feature = layers.Add()(
[multi_scale_feature_1, multi_scale_feature_2, multi_scale_feature_3]
)
gap = layers.GlobalAveragePooling2D()(combined_feature)
channel_wise_statistics = layers.Reshape((1, 1, channels))(gap)
compact_feature_representation = layers.Conv2D(
filters=channels // 8, kernel_size=(1, 1), activation="relu"
)(channel_wise_statistics)
feature_descriptor_1 = layers.Conv2D(
channels, kernel_size=(1, 1), activation="softmax"
)(compact_feature_representation)
feature_descriptor_2 = layers.Conv2D(
channels, kernel_size=(1, 1), activation="softmax"
)(compact_feature_representation)
feature_descriptor_3 = layers.Conv2D(
channels, kernel_size=(1, 1), activation="softmax"
)(compact_feature_representation)
feature_1 = multi_scale_feature_1 * feature_descriptor_1
feature_2 = multi_scale_feature_2 * feature_descriptor_2
feature_3 = multi_scale_feature_3 * feature_descriptor_3
aggregated_feature = layers.Add()([feature_1, feature_2, feature_3])
return aggregated_feature
"""
### Dual Attention Unit
The Dual Attention Unit or DAU is used to extract features in the convolutional streams.
While the SKFF block fuses information across multi-resolution branches, we also need a
mechanism to share information within a feature tensor, both along the spatial and the
channel dimensions which is done by the DAU block. The DAU suppresses less useful
features and only allows more informative ones to pass further. This feature
recalibration is achieved by using **Channel Attention** and **Spatial Attention**
mechanisms.
The **Channel Attention** branch exploits the inter-channel relationships of the
convolutional feature maps by applying squeeze and excitation operations. Given a feature
map, the squeeze operation applies Global Average Pooling across spatial dimensions to
encode global context, thus yielding a feature descriptor. The excitation operator passes
this feature descriptor through two convolutional layers followed by the sigmoid gating
and generates activations. Finally, the output of Channel Attention branch is obtained by
rescaling the input feature map with the output activations.
The **Spatial Attention** branch is designed to exploit the inter-spatial dependencies of
convolutional features. The goal of Spatial Attention is to generate a spatial attention
map and use it to recalibrate the incoming features. To generate the spatial attention
map, the Spatial Attention branch first independently applies Global Average Pooling and
Max Pooling operations on input features along the channel dimensions and concatenates
the outputs to form a resultant feature map which is then passed through a convolution
and sigmoid activation to obtain the spatial attention map. This spatial attention map is
then used to rescale the input feature map.

"""
class ChannelPooling(layers.Layer):
def __init__(self, axis=-1, *args, **kwargs):
super().__init__(*args, **kwargs)
self.axis = axis
self.concat = layers.Concatenate(axis=self.axis)
def call(self, inputs):
average_pooling = tf.expand_dims(tf.reduce_mean(inputs, axis=-1), axis=-1)
max_pooling = tf.expand_dims(tf.reduce_max(inputs, axis=-1), axis=-1)
return self.concat([average_pooling, max_pooling])
def get_config(self):
config = super().get_config()
config.update({"axis": self.axis})
def spatial_attention_block(input_tensor):
compressed_feature_map = ChannelPooling(axis=-1)(input_tensor)
feature_map = layers.Conv2D(1, kernel_size=(1, 1))(compressed_feature_map)
feature_map = keras.activations.sigmoid(feature_map)
return input_tensor * feature_map
def channel_attention_block(input_tensor):
channels = list(input_tensor.shape)[-1]
average_pooling = layers.GlobalAveragePooling2D()(input_tensor)
feature_descriptor = layers.Reshape((1, 1, channels))(average_pooling)
feature_activations = layers.Conv2D(
filters=channels // 8, kernel_size=(1, 1), activation="relu"
)(feature_descriptor)
feature_activations = layers.Conv2D(
filters=channels, kernel_size=(1, 1), activation="sigmoid"
)(feature_activations)
return input_tensor * feature_activations
def dual_attention_unit_block(input_tensor):
channels = list(input_tensor.shape)[-1]
feature_map = layers.Conv2D(
channels, kernel_size=(3, 3), padding="same", activation="relu"
)(input_tensor)
feature_map = layers.Conv2D(channels, kernel_size=(3, 3), padding="same")(
feature_map
)
channel_attention = channel_attention_block(feature_map)
spatial_attention = spatial_attention_block(feature_map)
concatenation = layers.Concatenate(axis=-1)([channel_attention, spatial_attention])
concatenation = layers.Conv2D(channels, kernel_size=(1, 1))(concatenation)
return layers.Add()([input_tensor, concatenation])
"""
### Multi-Scale Residual Block
The Multi-Scale Residual Block is capable of generating a spatially-precise output by
maintaining high-resolution representations, while receiving rich contextual information
from low-resolutions. The MRB consists of multiple (three in this paper)
fully-convolutional streams connected in parallel. It allows information exchange across
parallel streams in order to consolidate the high-resolution features with the help of
low-resolution features, and vice versa. The MIRNet employs a recursive residual design
(with skip connections) to ease the flow of information during the learning process. In
order to maintain the residual nature of our architecture, residual resizing modules are
used to perform downsampling and upsampling operations that are used in the Multi-scale
Residual Block.

"""
def down_sampling_module(input_tensor):
channels = list(input_tensor.shape)[-1]
main_branch = layers.Conv2D(channels, kernel_size=(1, 1), activation="relu")(
input_tensor
)
main_branch = layers.Conv2D(
channels, kernel_size=(3, 3), padding="same", activation="relu"
)(main_branch)
main_branch = layers.MaxPooling2D()(main_branch)
main_branch = layers.Conv2D(channels * 2, kernel_size=(1, 1))(main_branch)
skip_branch = layers.MaxPooling2D()(input_tensor)
skip_branch = layers.Conv2D(channels * 2, kernel_size=(1, 1))(skip_branch)
return layers.Add()([skip_branch, main_branch])
def up_sampling_module(input_tensor):
channels = list(input_tensor.shape)[-1]
main_branch = layers.Conv2D(channels, kernel_size=(1, 1), activation="relu")(
input_tensor
)
main_branch = layers.Conv2D(
channels, kernel_size=(3, 3), padding="same", activation="relu"
)(main_branch)
main_branch = layers.UpSampling2D()(main_branch)
main_branch = layers.Conv2D(channels // 2, kernel_size=(1, 1))(main_branch)
skip_branch = layers.UpSampling2D()(input_tensor)
skip_branch = layers.Conv2D(channels // 2, kernel_size=(1, 1))(skip_branch)
return layers.Add()([skip_branch, main_branch])
def multi_scale_residual_block(input_tensor, channels):
level1 = input_tensor
level2 = down_sampling_module(input_tensor)
level3 = down_sampling_module(level2)
level1_dau = dual_attention_unit_block(level1)
level2_dau = dual_attention_unit_block(level2)
level3_dau = dual_attention_unit_block(level3)
level1_skff = selective_kernel_feature_fusion(
level1_dau,
up_sampling_module(level2_dau),
up_sampling_module(up_sampling_module(level3_dau)),
)
level2_skff = selective_kernel_feature_fusion(
down_sampling_module(level1_dau),
level2_dau,
up_sampling_module(level3_dau),
)
level3_skff = selective_kernel_feature_fusion(
down_sampling_module(down_sampling_module(level1_dau)),
down_sampling_module(level2_dau),
level3_dau,
)
level1_dau_2 = dual_attention_unit_block(level1_skff)
level2_dau_2 = up_sampling_module((dual_attention_unit_block(level2_skff)))
level3_dau_2 = up_sampling_module(
up_sampling_module(dual_attention_unit_block(level3_skff))
)
skff_ = selective_kernel_feature_fusion(level1_dau_2, level2_dau_2, level3_dau_2)
conv = layers.Conv2D(channels, kernel_size=(3, 3), padding="same")(skff_)
return layers.Add()([input_tensor, conv])
"""
### MIRNet Model
"""
def recursive_residual_group(input_tensor, num_mrb, channels):
conv1 = layers.Conv2D(channels, kernel_size=(3, 3), padding="same")(input_tensor)
for _ in range(num_mrb):
conv1 = multi_scale_residual_block(conv1, channels)
conv2 = layers.Conv2D(channels, kernel_size=(3, 3), padding="same")(conv1)
return layers.Add()([conv2, input_tensor])
def mirnet_model(num_rrg, num_mrb, channels):
input_tensor = keras.Input(shape=[None, None, 3])
x1 = layers.Conv2D(channels, kernel_size=(3, 3), padding="same")(input_tensor)
for _ in range(num_rrg):
x1 = recursive_residual_group(x1, num_mrb, channels)
conv = layers.Conv2D(3, kernel_size=(3, 3), padding="same")(x1)
output_tensor = layers.Add()([input_tensor, conv])
return keras.Model(input_tensor, output_tensor)
model = mirnet_model(num_rrg=3, num_mrb=2, channels=64)
"""
## Training
- We train MIRNet using **Charbonnier Loss** as the loss function and **Adam
Optimizer** with a learning rate of `1e-4`.
- We use **Peak Signal Noise Ratio** or PSNR as a metric which is an expression for the
ratio between the maximum possible value (power) of a signal and the power of distorting
noise that affects the quality of its representation.
"""
def charbonnier_loss(y_true, y_pred):
return tf.reduce_mean(tf.sqrt(tf.square(y_true - y_pred) + tf.square(1e-3)))
def peak_signal_noise_ratio(y_true, y_pred):
return tf.image.psnr(y_pred, y_true, max_val=255.0)
optimizer = keras.optimizers.Adam(learning_rate=1e-4)
model.compile(
optimizer=optimizer,
loss=charbonnier_loss,
metrics=[peak_signal_noise_ratio],
)
history = model.fit(
train_dataset,
validation_data=val_dataset,
epochs=50,
callbacks=[
keras.callbacks.ReduceLROnPlateau(
monitor="val_peak_signal_noise_ratio",
factor=0.5,
patience=5,
verbose=1,
min_delta=1e-7,
mode="max",
)
],
)
def plot_history(value, name):
plt.plot(history.history[value], label=f"train_{name.lower()}")
plt.plot(history.history[f"val_{value}"], label=f"val_{name.lower()}")
plt.xlabel("Epochs")
plt.ylabel(name)
plt.title(f"Train and Validation {name} Over Epochs", fontsize=14)
plt.legend()
plt.grid()
plt.show()
plot_history("loss", "Loss")
plot_history("peak_signal_noise_ratio", "PSNR")
"""
## Inference
"""
def plot_results(images, titles, figure_size=(12, 12)):
fig = plt.figure(figsize=figure_size)
for i in range(len(images)):
fig.add_subplot(1, len(images), i + 1).set_title(titles[i])
_ = plt.imshow(images[i])
plt.axis("off")
plt.show()
def infer(original_image):
image = keras.utils.img_to_array(original_image)
image = image.astype("float32") / 255.0
image = np.expand_dims(image, axis=0)
output = model.predict(image, verbose=0)
output_image = output[0] * 255.0
output_image = output_image.clip(0, 255)
output_image = output_image.reshape(
(np.shape(output_image)[0], np.shape(output_image)[1], 3)
)
output_image = Image.fromarray(np.uint8(output_image))
original_image = Image.fromarray(np.uint8(original_image))
return output_image
"""
### Inference on Test Images
We compare the test images from LOLDataset enhanced by MIRNet with images
enhanced via the `PIL.ImageOps.autocontrast()` function.
You can use the trained model hosted on [Hugging Face Hub](https://huggingface.co/keras-io/lowlight-enhance-mirnet)
and try the demo on [Hugging Face Spaces](https://huggingface.co/spaces/keras-io/Enhance_Low_Light_Image).
"""
for low_light_image in random.sample(test_low_light_images, 6):
original_image = Image.open(low_light_image)
enhanced_image = infer(original_image)
plot_results(
[original_image, ImageOps.autocontrast(original_image), enhanced_image],
["Original", "PIL Autocontrast", "MIRNet Enhanced"],
(20, 12),
)
