
Real-time collaboration for Jupyter Notebooks, Linux Terminals, LaTeX, VS Code, R IDE, and more,
all in one place. Commercial Alternative to JupyterHub.
Real-time collaboration for Jupyter Notebooks, Linux Terminals, LaTeX, VS Code, R IDE, and more,
all in one place. Commercial Alternative to JupyterHub.
Path: blob/master/Natural Language Processing with Attention Models/Week 1 - Neural Machine Translation/C4_W1_Assignment.ipynb
Views: 13373
Assignment 1: Neural Machine Translation
Welcome to the first assignment of Course 4. Here, you will build an English-to-German neural machine translation (NMT) model using Long Short-Term Memory (LSTM) networks with attention. Machine translation is an important task in natural language processing and could be useful not only for translating one language to another but also for word sense disambiguation (e.g. determining whether the word "bank" refers to the financial bank, or the land alongside a river). Implementing this using just a Recurrent Neural Network (RNN) with LSTMs can work for short to medium length sentences but can result in vanishing gradients for very long sequences. To solve this, you will be adding an attention mechanism to allow the decoder to access all relevant parts of the input sentence regardless of its length. By completing this assignment, you will:
learn how to preprocess your training and evaluation data
implement an encoder-decoder system with attention
understand how attention works
build the NMT model from scratch using Trax
generate translations using greedy and Minimum Bayes Risk (MBR) decoding
Outline
1.1 Importing the Data
We will first start by importing the packages we will use in this assignment. As in the previous course of this specialization, we will use the Trax library created and maintained by the Google Brain team to do most of the heavy lifting. It provides submodules to fetch and process the datasets, as well as build and train the model.
INFO:tensorflow:tokens_length=568 inputs_length=512 targets_length=114 noise_density=0.15 mean_noise_span_length=3.0
trax 1.3.4
WARNING: You are using pip version 20.1.1; however, version 20.3.3 is available.
You should consider upgrading via the '/opt/conda/bin/python3 -m pip install --upgrade pip' command.
Next, we will import the dataset we will use to train the model. To meet the storage constraints in this lab environment, we will just use a small dataset from Opus, a growing collection of translated texts from the web. Particularly, we will get an English to German translation subset specified as opus/medical which has medical related texts. If storage is not an issue, you can opt to get a larger corpus such as the English to German translation dataset from ParaCrawl, a large multi-lingual translation dataset created by the European Union. Both of these datasets are available via Tensorflow Datasets (TFDS) and you can browse through the other available datasets here. We have downloaded the data for you in the data/ directory of your workspace. As you'll see below, you can easily access this dataset from TFDS with trax.data.TFDS. The result is a python generator function yielding tuples. Use the keys argument to select what appears at which position in the tuple. For example, keys=('en', 'de') below will return pairs as (English sentence, German sentence).
Notice that TFDS returns a generator function, not a generator. This is because in Python, you cannot reset generators so you cannot go back to a previously yielded value. During deep learning training, you use Stochastic Gradient Descent and don't actually need to go back -- but it is sometimes good to be able to do that, and that's where the functions come in. It is actually very common to use generator functions in Python -- e.g., zip is a generator function. You can read more about Python generators to understand why we use them. Let's print a a sample pair from our train and eval data. Notice that the raw ouput is represented in bytes (denoted by the b' prefix) and these will be converted to strings internally in the next steps.
train data (en, de) tuple: (b'Tel: +421 2 57 103 777\n', b'Tel: +421 2 57 103 777\n')
eval data (en, de) tuple: (b'Lutropin alfa Subcutaneous use.\n', b'Pulver zur Injektion Lutropin alfa Subkutane Anwendung\n')
1.2 Tokenization and Formatting
Now that we have imported our corpus, we will be preprocessing the sentences into a format that our model can accept. This will be composed of several steps:
Tokenizing the sentences using subword representations: As you've learned in the earlier courses of this specialization, we want to represent each sentence as an array of integers instead of strings. For our application, we will use subword representations to tokenize our sentences. This is a common technique to avoid out-of-vocabulary words by allowing parts of words to be represented separately. For example, instead of having separate entries in your vocabulary for --"fear", "fearless", "fearsome", "some", and "less"--, you can simply store --"fear", "some", and "less"-- then allow your tokenizer to combine these subwords when needed. This allows it to be more flexible so you won't have to save uncommon words explicitly in your vocabulary (e.g. stylebender, nonce, etc). Tokenizing is done with the trax.data.Tokenize() command and we have provided you the combined subword vocabulary for English and German (i.e. ende_32k.subword) saved in the data directory. Feel free to open this file to see how the subwords look like.
Append an end-of-sentence token to each sentence: We will assign a token (i.e. in this case 1) to mark the end of a sentence. This will be useful in inference/prediction so we'll know that the model has completed the translation.
Filter long sentences: We will place a limit on the number of tokens per sentence to ensure we won't run out of memory. This is done with the trax.data.FilterByLength() method and you can see its syntax below.
Single tokenized example input: [ 2538 2248 30 12114 23184 16889 5 2 20852 6456 20592 5812
3932 96 5178 3851 30 7891 3550 30650 4729 992 1]
Single tokenized example target: [ 1872 11 3544 39 7019 17877 30432 23 6845 10 14222 47
4004 18 21674 5 27467 9513 920 188 10630 18 3550 30650
4729 992 1]
1.3 tokenize & detokenize helper functions
Given any data set, you have to be able to map words to their indices, and indices to their words. The inputs and outputs to your trax models are usually tensors of numbers where each number corresponds to a word. If you were to process your data manually, you would have to make use of the following:
word2Ind: a dictionary mapping the word to its index.
ind2Word: a dictionary mapping the index to its word.
word2Count: a dictionary mapping the word to the number of times it appears.
num_words: total number of words that have appeared.
Since you have already implemented these in previous assignments of the specialization, we will provide you with helper functions that will do this for you. Run the cell below to get the following functions:
tokenize(): converts a text sentence to its corresponding token list (i.e. list of indices). Also converts words to subwords (parts of words).
detokenize(): converts a token list to its corresponding sentence (i.e. string).
Let's see how we might use these functions:
Single detokenized example input: During treatment with olanzapine, adolescents gained significantly more weight compared with adults.
Single detokenized example target: Während der Behandlung mit Olanzapin nahmen die Jugendlichen im Vergleich zu Erwachsenen signifikant mehr Gewicht zu.
tokenize('hello'): [[17332 140 1]]
detokenize([17332, 140, 1]): hello
1.4 Bucketing
Bucketing the tokenized sentences is an important technique used to speed up training in NLP. Here is a nice article describing it in detail but the gist is very simple. Our inputs have variable lengths and you want to make these the same when batching groups of sentences together. One way to do that is to pad each sentence to the length of the longest sentence in the dataset. This might lead to some wasted computation though. For example, if there are multiple short sentences with just two tokens, do we want to pad these when the longest sentence is composed of a 100 tokens? Instead of padding with 0s to the maximum length of a sentence each time, we can group our tokenized sentences by length and bucket, as on this image (from the article above):
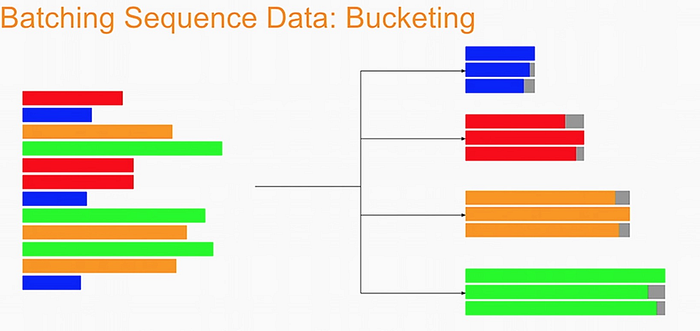
We batch the sentences with similar length together (e.g. the blue sentences in the image above) and only add minimal padding to make them have equal length (usually up to the nearest power of two). This allows to waste less computation when processing padded sequences. In Trax, it is implemented in the bucket_by_length function.
1.5 Exploring the data
We will now be displaying some of our data. You will see that the functions defined above (i.e. tokenize() and detokenize()) do the same things you have been doing again and again throughout the specialization. We gave these so you can focus more on building the model from scratch. Let us first get the data generator and get one batch of the data.
The input_batch and target_batch are Numpy arrays consisting of tokenized English sentences and German sentences respectively. These tokens will later be used to produce embedding vectors for each word in the sentence (so the embedding for a sentence will be a matrix). The number of sentences in each batch is usually a power of 2 for optimal computer memory usage.
We can now visually inspect some of the data. You can run the cell below several times to shuffle through the sentences. Just to note, while this is a standard data set that is used widely, it does have some known wrong translations. With that, let's pick a random sentence and print its tokenized representation.
THIS IS THE ENGLISH SENTENCE:
s categories: very common (≥ 1/ 10); common (≥ 1/ 100, < 1/ 10).
THIS IS THE TOKENIZED VERSION OF THE ENGLISH SENTENCE:
[ 14 2060 64 173 568 5426 30650 4048 5701 3771 115 135
6722 349 8076 568 5426 30650 4048 5701 3771 115 135 6722
812 2294 33287 913 135 6722 349 33022 30650 4729 992 1
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0]
THIS IS THE GERMAN TRANSLATION:
aufgeführt: sehr häufig (≥ 1/10); häufig (≥ 1/100, < 1/10).
THIS IS THE TOKENIZED VERSION OF THE GERMAN TRANSLATION:
[ 9675 64 200 2020 5426 30650 4048 5701 3771 115 135 123
349 8076 2020 5426 30650 4048 5701 3771 115 135 123 812
2294 33287 913 135 123 349 33022 30650 4729 992 1 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0]
2.1 Attention Overview
The model we will be building uses an encoder-decoder architecture. This Recurrent Neural Network (RNN) will take in a tokenized version of a sentence in its encoder, then passes it on to the decoder for translation. As mentioned in the lectures, just using a a regular sequence-to-sequence model with LSTMs will work effectively for short to medium sentences but will start to degrade for longer ones. You can picture it like the figure below where all of the context of the input sentence is compressed into one vector that is passed into the decoder block. You can see how this will be an issue for very long sentences (e.g. 100 tokens or more) because the context of the first parts of the input will have very little effect on the final vector passed to the decoder.

Adding an attention layer to this model avoids this problem by giving the decoder access to all parts of the input sentence. To illustrate, let's just use a 4-word input sentence as shown below. Remember that a hidden state is produced at each timestep of the encoder (represented by the orange rectangles). These are all passed to the attention layer and each are given a score given the current activation (i.e. hidden state) of the decoder. For instance, let's consider the figure below where the first prediction "Wie" is already made. To produce the next prediction, the attention layer will first receive all the encoder hidden states (i.e. orange rectangles) as well as the decoder hidden state when producing the word "Wie" (i.e. first green rectangle). Given these information, it will score each of the encoder hidden states to know which one the decoder should focus on to produce the next word. The result of the model training might have learned that it should align to the second encoder hidden state and subsequently assigns a high probability to the word "geht". If we are using greedy decoding, we will output the said word as the next symbol, then restart the process to produce the next word until we reach an end-of-sentence prediction.

There are different ways to implement attention and the one we'll use for this assignment is the Scaled Dot Product Attention which has the form:
You will dive deeper into this equation in the next week but for now, you can think of it as computing scores using queries (Q) and keys (K), followed by a multiplication of values (V) to get a context vector at a particular timestep of the decoder. This context vector is fed to the decoder RNN to get a set of probabilities for the next predicted word. The division by square root of the keys dimensionality () is for improving model performance and you'll also learn more about it next week. For our machine translation application, the encoder activations (i.e. encoder hidden states) will be the keys and values, while the decoder activations (i.e. decoder hidden states) will be the queries.
You will see in the upcoming sections that this complex architecture and mechanism can be implemented with just a few lines of code. Let's get started!
2.2 Helper functions
We will first implement a few functions that we will use later on. These will be for the input encoder, pre-attention decoder, and preparation of the queries, keys, values, and mask.
2.2.1 Input encoder
The input encoder runs on the input tokens, creates its embeddings, and feeds it to an LSTM network. This outputs the activations that will be the keys and values for attention. It is a Serial network which uses:
tl.Embedding: Converts each token to its vector representation. In this case, it is the the size of the vocabulary by the dimension of the model:
tl.Embedding(vocab_size, d_model).vocab_sizeis the number of entries in the given vocabulary.d_modelis the number of elements in the word embedding.tl.LSTM: LSTM layer of size
d_model. We want to be able to configure how many encoder layers we have so remember to create LSTM layers equal to the number of then_encoder_layersparameter.

Exercise 01
Instructions: Implement the input_encoder_fn function.
Note: To make this notebook more neat, we moved the unit tests to a separate file called w1_unittest.py. Feel free to open it from your workspace if needed. Just click File on the upper left corner of this page then Open to see your Jupyter workspace directory. From there, you can see w1_unittest.py and you can open it in another tab or download to see the unit tests. We have placed comments in that file to indicate which functions are testing which part of the assignment (e.g. test_input_encoder_fn() has the unit tests for UNQ_C1).
All tests passed
2.2.2 Pre-attention decoder
The pre-attention decoder runs on the targets and creates activations that are used as queries in attention. This is a Serial network which is composed of the following:
tl.ShiftRight: This pads a token to the beginning of your target tokens (e.g.
[8, 34, 12]shifted right is[0, 8, 34, 12]). This will act like a start-of-sentence token that will be the first input to the decoder. During training, this shift also allows the target tokens to be passed as input to do teacher forcing.tl.Embedding: Like in the previous function, this converts each token to its vector representation. In this case, it is the the size of the vocabulary by the dimension of the model:
tl.Embedding(vocab_size, d_model).vocab_sizeis the number of entries in the given vocabulary.d_modelis the number of elements in the word embedding.tl.LSTM: LSTM layer of size
d_model.

Exercise 02
Instructions: Implement the pre_attention_decoder_fn function.
All tests passed
2.2.3 Preparing the attention input
This function will prepare the inputs to the attention layer. We want to take in the encoder and pre-attention decoder activations and assign it to the queries, keys, and values. In addition, another output here will be the mask to distinguish real tokens from padding tokens. This mask will be used internally by Trax when computing the softmax so padding tokens will not have an effect on the computated probabilities. From the data preparation steps in Section 1 of this assignment, you should know which tokens in the input correspond to padding.
We have filled the last two lines in composing the mask for you because it includes a concept that will be discussed further next week. This is related to multiheaded attention which you can think of right now as computing the attention multiple times to improve the model's predictions. It is required to consider this additional axis in the output so we've included it already but you don't need to analyze it just yet. What's important now is for you to know which should be the queries, keys, and values, as well as to initialize the mask.
Exercise 03
Instructions: Implement the prepare_attention_input function
All tests passed
2.3 Implementation Overview
We are now ready to implement our sequence-to-sequence model with attention. This will be a Serial network and is illustrated in the diagram below. It shows the layers you'll be using in Trax and you'll see that each step can be implemented quite easily with one line commands. We've placed several links to the documentation for each relevant layer in the discussion after the figure below.

Exercise 04
Instructions: Implement the NMTAttn function below to define your machine translation model which uses attention. We have left hyperlinks below pointing to the Trax documentation of the relevant layers. Remember to consult it to get tips on what parameters to pass.
Step 0: Prepare the input encoder and pre-attention decoder branches. You have already defined this earlier as helper functions so it's just a matter of calling those functions and assigning it to variables.
Step 1: Create a Serial network. This will stack the layers in the next steps one after the other. Like the earlier exercises, you can use tl.Serial.
Step 2: Make a copy of the input and target tokens. As you see in the diagram above, the input and target tokens will be fed into different layers of the model. You can use tl.Select layer to create copies of these tokens. Arrange them as [input tokens, target tokens, input tokens, target tokens].
Step 3: Create a parallel branch to feed the input tokens to the input_encoder and the target tokens to the pre_attention_decoder. You can use tl.Parallel to create these sublayers in parallel. Remember to pass the variables you defined in Step 0 as parameters to this layer.
Step 4: Next, call the prepare_attention_input function to convert the encoder and pre-attention decoder activations to a format that the attention layer will accept. You can use tl.Fn to call this function. Note: Pass the prepare_attention_input function as the f parameter in tl.Fn without any arguments or parenthesis.
Step 5: We will now feed the (queries, keys, values, and mask) to the tl.AttentionQKV layer. This computes the scaled dot product attention and outputs the attention weights and mask. Take note that although it is a one liner, this layer is actually composed of a deep network made up of several branches. We'll show the implementation taken here to see the different layers used.
Having deep layers pose the risk of vanishing gradients during training and we would want to mitigate that. To improve the ability of the network to learn, we can insert a tl.Residual layer to add the output of AttentionQKV with the queries input. You can do this in trax by simply nesting the AttentionQKV layer inside the Residual layer. The library will take care of branching and adding for you.
Step 6: We will not need the mask for the model we're building so we can safely drop it. At this point in the network, the signal stack currently has [attention activations, mask, target tokens] and you can use tl.Select to output just [attention activations, target tokens].
Step 7: We can now feed the attention weighted output to the LSTM decoder. We can stack multiple tl.LSTM layers to improve the output so remember to append LSTMs equal to the number defined by n_decoder_layers parameter to the model.
Step 8: We want to determine the probabilities of each subword in the vocabulary and you can set this up easily with a tl.Dense layer by making its size equal to the size of our vocabulary.
Step 9: Normalize the output to log probabilities by passing the activations in Step 8 to a tl.LogSoftmax layer.
All tests passed
Expected Output:
Part 3: Training
We will now be training our model in this section. Doing supervised training in Trax is pretty straightforward (short example here). We will be instantiating three classes for this: TrainTask, EvalTask, and Loop. Let's take a closer look at each of these in the sections below.
3.1 TrainTask
The TrainTask class allows us to define the labeled data to use for training and the feedback mechanisms to compute the loss and update the weights.
Exercise 05
Instructions: Instantiate a train task.
All tests passed
3.2 EvalTask
The EvalTask on the other hand allows us to see how the model is doing while training. For our application, we want it to report the cross entropy loss and accuracy.
3.3 Loop
The Loop class defines the model we will train as well as the train and eval tasks to execute. Its run() method allows us to execute the training for a specified number of steps.
Part 4: Testing
We will now be using the model you just trained to translate English sentences to German. We will implement this with two functions: The first allows you to identify the next symbol (i.e. output token). The second one takes care of combining the entire translated string.
We will start by first loading in a pre-trained copy of the model you just coded. Please run the cell below to do just that.
4.1 Decoding
As discussed in the lectures, there are several ways to get the next token when translating a sentence. For instance, we can just get the most probable token at each step (i.e. greedy decoding) or get a sample from a distribution. We can generalize the implementation of these two approaches by using the tl.logsoftmax_sample() method. Let's briefly look at its implementation:
The key things to take away here are: 1. it gets random samples with the same shape as your input (i.e. log_probs), and 2. the amount of "noise" added to the input by these random samples is scaled by a temperature setting. You'll notice that setting it to 0 will just make the return statement equal to getting the argmax of log_probs. This will come in handy later.
Exercise 06
Instructions: Implement the next_symbol() function that takes in the input_tokens and the cur_output_tokens, then return the index of the next word. You can click below for hints in completing this exercise.
Click Here for Hints
- To get the next power of two, you can compute 2^log_2(token_length + 1) . We add 1 to avoid log(0).
- You can use np.ceil() to get the ceiling of a float.
- np.log2() will get the logarithm base 2 of a value
- int() will cast a value into an integer type
- From the model diagram in part 2, you know that it takes two inputs. You can feed these with this syntax to get the model outputs: model((input1, input2)). It's up to you to determine which variables below to substitute for input1 and input2. Remember also from the diagram that the output has two elements: [log probabilities, target tokens]. You won't need the target tokens so we assigned it to _ below for you.
- The log probabilities output will have the shape: (batch size, decoder length, vocab size). It will contain log probabilities for each token in the cur_output_tokens plus 1 for the start symbol introduced by the ShiftRight in the preattention decoder. For example, if cur_output_tokens is [1, 2, 5], the model will output an array of log probabilities each for tokens 0 (start symbol), 1, 2, and 5. To generate the next symbol, you just want to get the log probabilities associated with the last token (i.e. token 5 at index 3). You can slice the model output at [0, 3, :] to get this. It will be up to you to generalize this for any length of cur_output_tokens
All tests passed
Now you will implement the sampling_decode() function. This will call the next_symbol() function above several times until the next output is the end-of-sentence token (i.e. EOS). It takes in an input string and returns the translated version of that string.
Exercise 07
Instructions: Implement the sampling_decode() function.
All tests passed
We have set a default value of 0 to the temperature setting in our implementation of sampling_decode() above. As you may have noticed in the logsoftmax_sample() method, this setting will ultimately result in greedy decoding. As mentioned in the lectures, this algorithm generates the translation by getting the most probable word at each step. It gets the argmax of the output array of your model and then returns that index. See the testing function and sample inputs below. You'll notice that the output will remain the same each time you run it.
4.2 Minimum Bayes-Risk Decoding
As mentioned in the lectures, getting the most probable token at each step may not necessarily produce the best results. Another approach is to do Minimum Bayes Risk Decoding or MBR. The general steps to implement this are:
take several random samples
score each sample against all other samples
select the one with the highest score
You will be building helper functions for these steps in the following sections.
4.2.2 Comparing overlaps
Let us now build our functions to compare a sample against another. There are several metrics available as shown in the lectures and you can try experimenting with any one of these. For this assignment, we will be calculating scores for unigram overlaps. One of the more simple metrics is the Jaccard similarity which gets the intersection over union of two sets. We've already implemented it below for your perusal.
One of the more commonly used metrics in machine translation is the ROUGE score. For unigrams, this is called ROUGE-1 and as shown in class, you can output the scores for both precision and recall when comparing two samples. To get the final score, you will want to compute the F1-score as given by:
Exercise 08
Instructions: Implement the rouge1_similarity() function.
All tests passed
4.2.3 Overall score
We will now build a function to generate the overall score for a particular sample. As mentioned earlier, we need to compare each sample with all other samples. For instance, if we generated 30 sentences, we will need to compare sentence 1 to sentences 2 to 30. Then, we compare sentence 2 to sentences 1 and 3 to 30, and so forth. At each step, we get the average score of all comparisons to get the overall score for a particular sample. To illustrate, these will be the steps to generate the scores of a 4-sample list.
Get similarity score between sample 1 and sample 2
Get similarity score between sample 1 and sample 3
Get similarity score between sample 1 and sample 4
Get average score of the first 3 steps. This will be the overall score of sample 1.
Iterate and repeat until samples 1 to 4 have overall scores.
We will be storing the results in a dictionary for easy lookups.
Exercise 09
Instructions: Implement the average_overlap() function.
All tests passed
In practice, it is also common to see the weighted mean being used to calculate the overall score instead of just the arithmetic mean. We have implemented it below and you can use it in your experiements to see which one will give better results.
4.2.4 Putting it all together
We will now put everything together and develop the mbr_decode() function. Please use the helper functions you just developed to complete this. You will want to generate samples, get the score for each sample, get the highest score among all samples, then detokenize this sample to get the translated sentence.
Exercise 10
Instructions: Implement the mbr_overlap() function.
This unit test take a while to run. Please be patient
All tests passed