{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"\n",
"As a reminder, one of the prerequisites for this course if programming experience, especially in Python. If you do not have experience in Python specifically, we
strongly recommend you go through the
Codecademy Python course as soon as possible to brush up on the basics of Python.\n",
"
Before going through this notebook, you may want to take a quick look at [7 - Debugging.ipynb](7 - Debugging.ipynb) if you haven't already for some tips on debugging your code when you get stuck.
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"import numpy as np"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"## Loading and saving data"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"Often when we are working with models, we will need to load data that does not currently exist within the Python environment. Additionally, as we create data within the Python environment, we may want to save it to disk, so that we can have access to it again later (i.e., if the IPython kernel is restarted).\n",
"\n",
"One common use case for this is if we have a computationally intensive model that takes a long time to run. If we save out the data from the model after it finishes running, then we don't have to wait for it to run every time we want to use that data.\n",
"\n",
"Another other common use case is when you have data from a different source -- for example, someone else's dataset, or perhaps human data you collected by hand. In these cases, we need to be able to load the existing data into our Python environment before we can do anything with it."
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"### Loading"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"Numpy arrays are typically stored with an extension of `.npy` or `.npz`. The `.npy` extension means that the file only contains a single numpy array, while the `.npz` extension indicates that there are multiple arrays saved in the file. To load either type of data, we use the `np.load` function, and provide a path to the data."
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
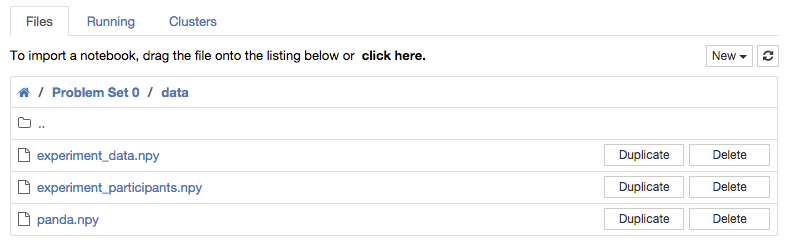
"If you go back to the notebook list, you'll see a directory called `data`. This directory is on the file system of the server that hosts this notebook. If you click on the directory, you'll see three files, `experiment_data.npy`, `experiment_participants.npy`, and `panda.npy`. For now, we'll be paying attention to the first two files (the `panda.npy` file will be used later on in this problem):\n",
"\n",
"\n",
"\n",
"(Note: it is possible that you will see more files that that, if you have already run through this notebook or other notebooks.)"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"Let's load the `experiment_data.npy` file. We're currently in the `Problem Set 0` directory, so we just need to specify the `data` directory beneath that:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"x = np.load(\"data/experiment_data.npy\")\n",
"x"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"We can also load the participants:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"p = np.load(\"data/experiment_participants.npy\")\n",
"p"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"### Saving"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"Let's say we wanted to save a copy of `data`. To do this, we use `np.save`, with the desired filename as the first argument and the numpy array as the second argument:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"np.save(\"data/experiment_data_copy.npy\", x)"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"After running the above cell, your `data/` directory should look like this:\n",
"\n",
"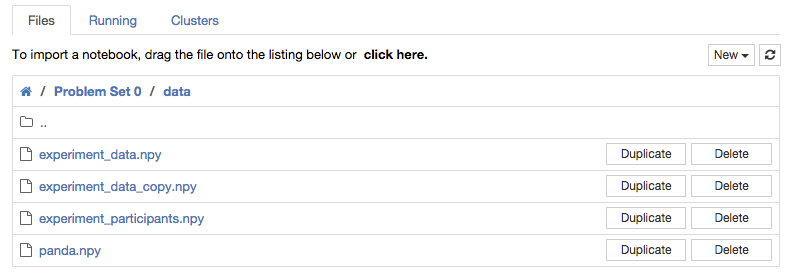"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"What if we wanted to save our data and our participants into the *same* file? We can do this with a different function, called `np.savez`. This takes as arguments the path to the data, followed by all the arrays we want to save. We use keyword arguments in order to specify the name of each array: `x` (the array holding our experiment data) will be saved under the key `data`, and `p` (the array of experiment participants) will be saved under the key `participants`:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"np.savez(\n",
" \"data/experiment.npz\",\n",
" data=x,\n",
" participants=p)"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"Note that we used the extension of `.npz` for this file, to indicate that it contains multiple arrays.\n",
"\n",
"After saving this data, we should see the file in our `data/` directory:\n",
"\n",
"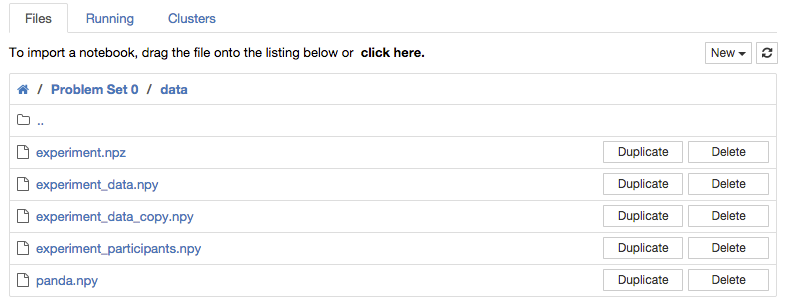"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"Now, if we were to load this data back in, we don't immediately get an array, but a special `NpzFile` object:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"experiment = np.load(\"data/experiment.npz\")\n",
"experiment"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"This special object acts like a dictionary. We can see what arrays are in this object using the `keys()` method:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"experiment.keys()"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"And we can extract each array by accessing it as we would if `experiment` were a dictionary:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"experiment['data']"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"experiment['participants']"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"### Exercise: Saving files (0.5 points)"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"Write code to save a new `.npz` file which also contains the `data` and `participant` arrays (just like with `data/experiment.npz`). Your new file should additionally contain an array called \"trials\", which is a 1D array of integers from 1 to 300 (inclusive). You will need to create this array yourself. \n",
"\n",
"Save your file under the name `full_experiment.npz` into the `data/` directory."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true,
"nbgrader": {
"grade": false,
"grade_id": "save_data",
"locked": false,
"points": 0.0,
"schema_version": 1,
"solution": true
}
},
"outputs": [],
"source": [
"# load the existing data\n",
"data = np.load(\"data/experiment_data.npy\")\n",
"participants = np.load(\"data/experiment_participants.npy\")\n",
"\n",
"### BEGIN SOLUTION\n",
"np.savez(\n",
" \"data/full_experiment.npz\",\n",
" data=data,\n",
" participants=participants,\n",
" trials=np.arange(1, 301))\n",
"### END SOLUTION"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"# add your own test cases in this cell!\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": true,
"grade_id": "test_save_data",
"locked": false,
"points": 0.5,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"from numpy.testing import assert_array_equal\n",
"\n",
"# load the relevant data\n",
"data = np.load(\"data/experiment_data.npy\")\n",
"participants = np.load(\"data/experiment_participants.npy\")\n",
"experiment = np.load(\"data/full_experiment.npz\")\n",
"\n",
"# make sure the data matches\n",
"assert experiment['data'].shape == (50, 300)\n",
"assert experiment['participants'].shape == (50,)\n",
"assert experiment['trials'].shape == (300,)\n",
"assert_array_equal(experiment['data'], data)\n",
"assert_array_equal(experiment['participants'], participants)\n",
"assert_array_equal(experiment['trials'], np.arange(1, 301))\n",
"\n",
"print(\"Success!\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"## Vectorized operations on multidimensional arrays"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"Let's take a look at the data from the previous part of the problem a little more closely. This data is response times from a (hypothetical) psychology experiment, collected over 300 trials for 50 participants. Thus, if we look at the shape of the data, we see that the participants correspond to the *rows*, and the trials correspond to the *columns*:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"experiment = np.load(\"data/full_experiment.npz\")\n",
"data = experiment[\"data\"]\n",
"data.shape"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"In other words, element $(i, j)$ would be the $i^\\mathrm{th}$ participant's response time on trial $j$, in milliseconds.\n",
"\n",
"One question we might want to ask about this data is: are people getting faster at responding over time? It might be hard to tell from a single participant. For example, these are the response times of the first 10 trials from the first paraticipant:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"data[0, :10]"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"And these are the response times on the last 10 trials from the first participant:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"data[0, -10:]"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"At a glance, it looks like the last 10 trials might be slightly faster, but it is hard to know for sure because the data is fairly noisy. Another way to look at the data would be to see what the *average* response time is for each trial. This gives a measure of how quickly people can respond on each trial in a general sense.\n",
"\n",
"To compute the average response time for a trial, we can use the `np.mean` function. Here is the first trial:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"np.mean(data[:, 0])"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"And the last trial:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"np.mean(data[:, -1])"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"On average, response times are faster on the last trial than on the first trial. How would we compute this for all trials? One answer would be to use a list comprehension, like this:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"trial_means = [np.mean(data[:, i]) for i in range(300)]"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"However, the `np.mean` function can actually do this for us, without the need for a list comprehension. What we want to do is to take the *mean across participants*, or the *mean for each trial*. Participants correspond to the rows, or the *first dimension*, so we can tell numpy to take the mean across this first dimension with the `axis` flag (remember that 0-indexing is used in Python, so the *first* dimension corresponds to axis 0):"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"trial_means = np.mean(data, axis=0)"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"We can verify that we took the mean for each trial by checking the shape of `trial_means`:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"trial_means.shape"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"Checking the shape of your array after doing a computation over it is always a good idea, to verify that you did the computation over the correct axis. If we had accidentally used the wrong axis, our mistake would be readily apparent by checking the shape, because we know that if we want the mean for each trial, we should end up with an array of shape `(300,)`. However, if we use the wrong axis, this is not the case (we instead have the mean for every participant):"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"np.mean(data, axis=1).shape"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"Note that if we didn't specify the axis, the mean would be taken over the *entire* array:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"np.mean(data)"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"So, be careful about keeping track of the shapes of your arrays, and think about when you want to use an axis argument or not!"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"## Plotting"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"Now that we've computed the average response time for each trial, it would be useful to actually visualize it, so we can see a graph instead of just numbers. To plot things, we need a special magic function that will cause the graphs to be displayed inline in the notebook:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"%matplotlib inline"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"You only need to run this command once per notebook (though, note that if you restart the kernel, you'll need to run the command again). In most cases, we'll provide a cell with imports for you so you don't have to worry about remembering to include it. You additionally need to import the `pyplot` module from `matplotlib`:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"import matplotlib.pyplot as plt"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"Let's load our data in again, and compute some descriptive statistics, just to make it clearer what it is that we are going to be plotting. Recall that the `trials` array is an array from 1 to 300 (inclusive), corresponding to the trial numbers. This array will serve as our $x$-values:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"experiment = np.load(\"data/full_experiment.npz\")\n",
"trials = experiment[\"trials\"]\n",
"data = experiment[\"data\"]\n",
"\n",
"# compute mean and median response times for each trial\n",
"trial_mean = np.mean(data, axis=0)\n",
"trial_median = np.median(data, axis=0)"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"To plot things, we'll be using the `plt.subplots` function. Most of the time when we use it, we'll call it as `plt.subplots()`, which just produces a `figure` object (corresponding to the entire graph), and an `axis` object (corresponding to the set of axes we'll be plotting on):"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"figure, axis = plt.subplots()\n",
"print(\"Figure object: \" + str(figure))\n",
"print(\"Axis object: \" + str(axis))"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"The distinction between the figure and the axis is clearer when we want multiple subplots, which we can also do with `plt.subplots`, by passing it two arguments: the number of rows of subplots that we want, and the number of columns of subplots that we want. Then, the function will return a single object for the entire figure, and a separate object for each subplot axis:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"figure, (axis1, axis2, axis3) = plt.subplots(1, 3)\n",
"print(\"Figure object: \" + str(figure))\n",
"print(\"1st axis object: \" + str(axis1))\n",
"print(\"2nd axis object: \" + str(axis2))\n",
"print(\"3rd axis object: \" + str(axis3))"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"In general, the figure object is used for things like adjusting the overall size of the figure, while the axis objects are used for actually plotting data. So, once we have created our figure and axis (or axes), we plot our data on the specified axis using `axis.plot`. The third argument, `k`, is a shorthand for the color our data should be plotted in (in this case, black):"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"# create the figure\n",
"figure, axis = plt.subplots()\n",
"# plot the data\n",
"axis.plot(trials, trial_mean, 'k');"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Displaying multiple lines on the same axis is as easy as calling the `axis.plot` method again with new data! Below, we plot the trial means and medians as separate lines on the same plot, with means in black (`'k'`) and medians in blue (`'b'`). We also introduce a new argument, `label`, which we use to specify the name for each line in the legend. To display the final legend, we call `plt.legend()` after we have added all the data we wish to plot to our specified axis."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"# create a new figure\n",
"figure, axis = plt.subplots()\n",
"# plot the mean and median as separate lines\n",
"axis.plot(trials, trial_mean, 'k', label='Trial Means');\n",
"axis.plot(trials, trial_median, 'b', label='Trial Medians');\n",
"# display the legend \n",
"plt.legend();"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"A better visualization of this data would be points, rather than a line. To do this, we can change the `'k'` argument for trial means to `'ko'`, indicating that the data should again be plotted in black (`'k'`) and using a dot (`'o'`), and the `'b'` argument for trial medians to `'bs'` to plot them as blue (`'b'`) squares (`'s'`):"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"figure, axis = plt.subplots()\n",
"axis.plot(trials, trial_mean, 'ko', label='Trial Means');\n",
"axis.plot(trials, trial_median, 'bs', label='Trial Medians');\n",
"plt.legend();"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"We can also specify the color using a keyword argument and a RGB (red-green-blue) value. The following plots `trial_means` as green dots and `trial_medians` as red squares:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"figure, axis = plt.subplots()\n",
"axis.plot(trials, trial_mean, 'o', color=(0, 1, 0), label='Trial Means');\n",
"axis.plot(trials, trial_median, 's', color=(1, 0, 0), label='Trial Medians');\n",
"plt.legend();"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"For a full list of all the different color and marker symbols (like `'ko'`), take a look at the documentation on `axis.plot`:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"axis.plot?"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"Frequently, we will want to specify axis labels and a title for our plots, in order to be more descriptive about what is being visualized. To do this, we can use the `set_xlabel`, `set_ylabel`, and `set_title` commands:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"figure, axis = plt.subplots()\n",
"axis.plot(trials, trial_mean, 'ko', label='Trial Means');\n",
"axis.plot(trials, trial_median, 'bs', label='Trial Medians');\n",
"\n",
"# set the label for the x (horizontal) axis\n",
"axis.set_xlabel(\"Trial\")\n",
"# set the label for the y (vertical) axis\n",
"axis.set_ylabel(\"Response time (milliseconds)\")\n",
"# set the title\n",
"axis.set_title(\"Average participant response times by trial\");\n",
"\n",
"# display legend\n",
"plt.legend();"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"Another plotting function that we will use is `matshow`, which displays a heatmap using the values of 2D array. For example, if we wanted to display an array of pixel intensities, we could use `matshow` to do so.\n",
"\n",
"The file `data/panda.npy` contains an array of pixels that represent an image of a panda. As before, we can load in the data with `np.load`:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"# load the pixel data as a numpy array\n",
"img = np.load(\"data/panda.npy\")\n",
"# print the pixel intensity values\n",
"print('Raw pixel intensities:\\n'+str(img))"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"And now visualize the pixel intensity values using `matshow`:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"figure, axis = plt.subplots()\n",
"\n",
"# show the array in grayscale\n",
"axis.matshow(img, cmap='gray')\n",
"\n",
"# turn off the axis tickmarks\n",
"axis.set_xticks([])\n",
"axis.set_yticks([]);"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"It's important to specify that the colormap (or `cmap`) is `'gray'`, otherwise we end up with a crazy rainbow image!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"figure, axis = plt.subplots()\n",
"\n",
"# show the array in grayscale\n",
"axis.matshow(img)\n",
"\n",
"# turn off the axis tickmarks\n",
"axis.set_xticks([])\n",
"axis.set_yticks([]);"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"### Exercise: Squared exponential distance (4 points)"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"\n",
"This next exercise is going to be broken into two steps: first, we will write a function to compute a distance between two numbers, and then we will plot the result.\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"We are going to compute a *squared exponential distance*, which is given by the following equation:\n",
"\n",
"$$\n",
"D_{ij}=d(x_i, y_j)=e^\\frac{-(x_i-y_j)^2}{2}\n",
"$$\n",
"\n",
"where $x$ is a $n$-length vector and $y$ is a $m$-length vector. The variable $x_i$ corresponds to the $i^{th}$ element of $x$, and the variable $y_j$ corresponds to the $j^{th}$ element of $y$."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true,
"nbgrader": {
"grade": false,
"grade_id": "squared_exponential",
"locked": false,
"schema_version": 1,
"solution": true
}
},
"outputs": [],
"source": [
"def squared_exponential(x, y):\n",
" \"\"\"Computes a matrix of squared exponential distances between\n",
" the elements of x and y.\n",
"\n",
" Hint: your solution shouldn't require more than five lines\n",
" of code, including the return statement.\n",
"\n",
" Parameters\n",
" ----------\n",
" x : numpy array with shape (n,)\n",
" y : numpy array with shape (m,)\n",
"\n",
" Returns\n",
" -------\n",
" (n, m) array of distances\n",
"\n",
" \"\"\"\n",
" ### BEGIN SOLUTION\n",
" distances = np.zeros((x.size, y.size))\n",
" for i in range(x.size):\n",
" for j in range(y.size):\n",
" distances[i, j] = np.exp(-0.5 * (x[i] - y[j]) ** 2)\n",
" return distances\n",
" ### END SOLUTION"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"# add your own test cases in this cell!\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": true,
"grade_id": "test_squared_exponential",
"locked": false,
"points": 2.0,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"from numpy.testing import assert_allclose\n",
"from nose.tools import assert_equal\n",
"\n",
"d = squared_exponential(np.arange(3), np.arange(4))\n",
"assert_equal(d.shape, (3, 4))\n",
"assert_equal(d.dtype, float)\n",
"assert_allclose(d[0], [ 1. , 0.60653066, 0.13533528, 0.011108997])\n",
"assert_allclose(d[1], [ 0.60653066, 1. , 0.60653066, 0.13533528])\n",
"assert_allclose(d[2], [ 0.13533528, 0.60653066, 1. , 0.60653066])\n",
"\n",
"d = squared_exponential(np.arange(4), np.arange(3))\n",
"assert_equal(d.shape, (4, 3))\n",
"assert_equal(d.dtype, float)\n",
"assert_allclose(d[:, 0], [ 1. , 0.60653066, 0.13533528, 0.011108997])\n",
"assert_allclose(d[:, 1], [ 0.60653066, 1. , 0.60653066, 0.13533528])\n",
"assert_allclose(d[:, 2], [ 0.13533528, 0.60653066, 1. , 0.60653066])\n",
"\n",
"print(\"Success!\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"\n",
"Now, let's write a function to visualize these distances. Implement plot_squared_exponential to plot these distances using the matshow function.\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"Be sure to check the docstring of plot_squared_exponential for additional constraints -- going forward, in general we will give brief instructions in green cells like the one above, and more detailed instructions in the function comment.
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true,
"nbgrader": {
"grade": false,
"grade_id": "plot_squared_exponential",
"locked": false,
"schema_version": 1,
"solution": true
}
},
"outputs": [],
"source": [
"def plot_squared_exponential(axis, x, y):\n",
" \"\"\"Plot the squared exponential distance between the elements\n",
" of x and y. Make sure to:\n",
"\n",
" * call the `squared_exponential` function to compute the distances \n",
" between `x` and `y`\n",
" * use the grayscale colormap\n",
" * remember to include axis labels and a title. \n",
" * turn off the tick marks on both axes\n",
"\n",
" Parameters\n",
" ----------\n",
" axis : matplotlib axis object\n",
" The axis on which to plot the distances\n",
" x : numpy array with shape (n,)\n",
" y : numpy array with shape (m,)\n",
"\n",
" \"\"\"\n",
" ### BEGIN SOLUTION\n",
" distances = squared_exponential(x, y)\n",
" axis.matshow(distances, cmap='gray')\n",
" axis.set_xlabel(\"x\")\n",
" axis.set_ylabel(\"y\")\n",
" axis.set_xticks([])\n",
" axis.set_yticks([])\n",
" axis.set_title(\"Squared exponential\")\n",
" ### END SOLUTION"
]
},
{
"cell_type": "markdown",
"metadata": {
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"source": [
"Now, let's see what our squared exponential function actually looks like. To do this we will look at 100 linearly spaced values from -2 to 2 on the x axis and 100 linearly spaced values from -2 to 2 on the y axis. To generate these values we will use the function `np.linspace`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"x = np.linspace(-2, 2, 100)\n",
"y = np.linspace(-2, 2, 100)\n",
"\n",
"figure, axis = plt.subplots()\n",
"plot_squared_exponential(axis, x, y)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true,
"nbgrader": {
"grade": false,
"locked": false,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"# add your own test cases in this cell!\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false,
"nbgrader": {
"grade": true,
"grade_id": "test_plot_squared_exponential",
"locked": false,
"points": 2.0,
"schema_version": 1,
"solution": false
}
},
"outputs": [],
"source": [
"from plotchecker import assert_image_allclose, get_image_colormap\n",
"from numpy.testing import assert_array_equal\n",
"\n",
"# generate some random data\n",
"x = np.random.rand(100)\n",
"y = np.random.rand(75)\n",
"\n",
"# plot it\n",
"figure, axis = plt.subplots()\n",
"plot_squared_exponential(axis, x, y)\n",
"\n",
"# check image data\n",
"assert_image_allclose(axis, squared_exponential(x, y))\n",
"\n",
"# check that the 'gray' colormap was used\n",
"assert_equal(get_image_colormap(axis), 'gray')\n",
"\n",
"# check axis labels and title\n",
"assert axis.get_xlabel() != ''\n",
"assert axis.get_ylabel() != ''\n",
"assert axis.get_title() != ''\n",
"\n",
"# check that ticks are removed\n",
"assert_array_equal(axis.get_xticks(), [])\n",
"assert_array_equal(axis.get_yticks(), [])\n",
"\n",
"# close the plot\n",
"plt.close(figure)\n",
"\n",
"print(\"Success!\")"
]
}
],
"metadata": {
"celltoolbar": "Create Assignment",
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.4.0"
}
},
"nbformat": 4,
"nbformat_minor": 0
}