Пример работы с номинальными данными
Построение таблицы сопряжённости
Таблица сопряжённости представляет собой таблицу перекрёстных частот двух или более признаков. Они используются для анализа номинальных (категориальных) данных. Далее рассмотрим пример построения такой таблицы в случае двух признаков.
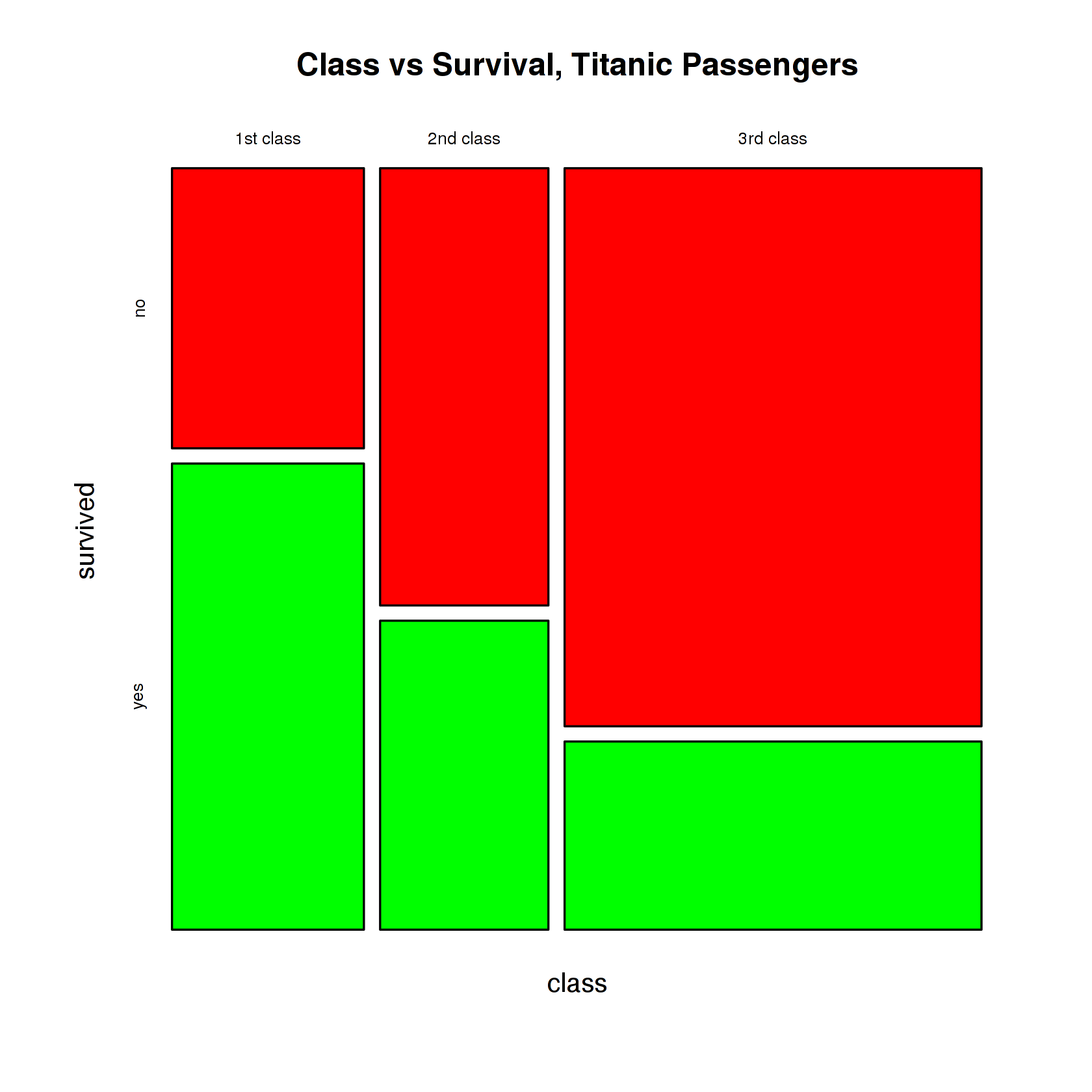
В качестве примера возьмём известный набор данных --- статистику о пассажирах "Титаника", в которой указаны возраст и пол пассажира, класс билета, а также метка выжил/не выжил. Пол, класс билета и сведения о выживаемости являются номинальными признаками (почему?). Исследуем, существует ли взаимосвязь между классом билета и выживанием (или по-другому: верно ли, что существуют значимые различия в выживаемости между пассажирами, имевшими билеты разных классов).
Чтобы показать, как строится таблица сопряжённости, возьмём несколько мысленных данных:
| Номер наблюдения | Класс билета | Выживаемость |
|---|---|---|
| 1 | Первый класс | Да |
| 2 | Второй класс | Да |
| 3 | Первый класс | Да |
| 4 | Третий класс | Нет |
| 5 | Третий класс | Нет |
| 6 | Третий класс | Да |
| 7 | Второй класс | Нет |
| 8 | Первый класс | Да |
| 9 | Первый класс | Нет |
| 10 | Второй класс | Да |
Признак "Класс билета" имеет градации: первый, второй и третий классы. Признак "Выживаемость" бинарный, т. е. имеет градации --- "Да", "Нет". Следовательно, таблица сопряжённости будет иметь размерность . Строки таблицы соответствуют градациям первого признака, столбцы --- градациям второго.
На пересечении строки и столбца мы должны поставить число --- количество объектов в выборке, для которых имеет место комбинация значений признаков. Например, в ячейке (она соответствует числу пассажиров первого класса, которые выжили) будет находиться число , в ячейке (число пассажиров первого класса, которые не выжили) --- число . Далее рассуждаем аналогично. Приведём конечный результат:
| Да | Нет | Сумма | |
|---|---|---|---|
| Первый класс | 3 | 1 | 4 |
| Второй класс | 2 | 1 | 3 |
| Третий класс | 1 | 2 | 3 |
| Сумма | 6 | 4 | 10 |
В последнем столбце производится подсчёт сумм частот по строкам. Эти числа представляют собой количество пассажиров первого, второго и третьего классов соответственно. В последней строке расположены суммы по столбцам --- это число выживших и невыживших пассажиров. Наконец, в правой нижней ячейке суммируем последний столбец либо строку (эти две суммы совпадают и равны длине выборки). Построение таблицы сопряжённости завершено.
Вычисление статистики хи-квадрат по формуле
Использование встроенных функций Sage (via scipy.stats)
Использование R