Введение
Краткая история
7 января 1954. Джорджтаунский эксперимент по машинному переводу с русского на английский;
1957 г., Ноам Хомский ввел "универсальную грамматику";
1961 г., Начинается сбор Брауновского корпуса;
конец 1960-х гг., ELIZA –- программа, ведущая психотерапевтические разговоры;
1975 г., Солтон ввел векторную модель (Vector Space Model, VSM);
до 1980–х. Методы решения задач, основанные на правилах;
после 1980–х гг., Методы решения задач, основанные на машинном обучении и корпусной лингвистике;
1998 г., Понте и Крофт вводят языковую модель (Language Model, LM);
конец 1990–х гг., Вероятностные тематические модели (LSI, pLSI, LDA, и т.д.);
1999 г., Опубликован учебник Маннинга и Щютце "Основы статистической автоматической обработки текстов" ("Foundations of Statistical Natural Language Processing");
2009 г.. Опубликован учебник Берда, Кляйна и Лопера "Автоматическая обработка текстов на Python" ("Natural Language Processing with Python);
Mikolov, Tomas и др. "Efficient estimation of word representations in vector space".
Основные задачи
Машинный перевод
Классификация текстов
Фильтрация спама
По тональности
По теме или жанру
Кластеризация текстов
Извлечение информации
Фактов и событий
Именованных сущностей
Вопросно-ответные системы
Суммаризация текстов
Генерация текстов
Распознавание речи
Проверка правописания
Оптическое распознавание символов
Пользовательские эксперименты и оценка точности и качества методов
Основные техники
Уровень символов:
Токенизация: разбиение текста на слова
Разбиение текста на предложения
Уровень слов – морфология:
Разметка частей речи
Снятие морфологической неоднозначности
Уровень предложений – синтаксис:
Выделенние именных или глагольных групп (chunking)
Выделенние семантических ролей
Деревья составляющих и зависимостей
Уровень смысла – семантика и дискурс:
Разрешение кореферентных связей
Анализ дискурсивных связей
Выделение синонимов
Анализ аргументативных связей
Основные проблемы
Неоднозначность
Лексическая неоднозначность: орган, парить, рожки, атлас
Морфологическая неоднозначность: Хранение денег в банке. Что делают белки в клетке?
Синтаксическая неоднозначность: Мужу изменять нельзя. Его удивил простой солдат.
Неологизмы: печеньки, заинстаграммить, репостнуть, расшарить, затащить, килорубли
Разные варианты написания: Россия, Российская Федерация, РФ
Нестандартное написание: каг дила?
Синтаксическая неоднозначность

I saw the man. The man was on the hill. I was using a telescope.
I saw the man. I was on the hill. I was using a telescope.
I saw the man. The man was on the hill. The hill had a telescope.
I saw the man. I was on the hill. The hill had a telescope.
I saw the man. The man was on the hill. I saw him using a telescope.
План
Морфология. Синтаксис. Извлечение ключевых слов и словосочетаний.
Векторная модель документа и информационный поиск. Векторная модель слова и дистрибутивная семантика. Методы снижения размерности. Тематическое моделирование, word2vec, GloVe
Классификация документов и классификация последовательностей. Сверточные нейронные сети, условные случайные поля.
Языковая модель. Нейронная языковая модель. Реккурентные нейронные сети. Извлечение именованных сущностей.
Токенизация и подсчет количества слов
Сколько слов в этом предложении?
На дворе трава, на траве дрова, не руби дрова на траве двора.*
** 12 токенов** : На, дворе, трава, на, траве, дрова, не, руби, дрова, на, траве, двора
** 8 - 9 типов** : Н/на, дворе, трава, траве, дрова, не, руби, двора.
** 6 лексем** : на, не, двор, трава, дрова, рубить
Токен и тип
** Тип ** – уникальное слово из текста
** Токен ** – тип и его позиция в тексте
Обозначения
= число токенов
– словарь (все типы)
= количество типов в словаре
** Как связаны и ?**
Закон Ципфа
В любом достаточно большом тексте ранг типа обратно пропорционален его частоте:
– частота типа, – ранг типа, – параметр, для славянских языков – около 0.07
Закон Хипса
С увеличением длины текста (количества токенов), количество типов увеличивается в соответствии с законом:
– число токенов, – количество типов в словаре, – параметры, обычно
Анализ новостных сообщений
Рассмотрим коллекцию новостных сообщений за первую половину 2017 года. Про каждое новостное сообщение известны:
его заголовок и текст
дата его публикации
событие, о котором это новостное сообщение написано
его рубрика
Предварительный анализ коллекции
Средняя длина текстов
Количество текстов о разных событиях
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
<ipython-input-2-4e6b87a33326> in <module>()
----> 1 from bokeh.charts import Bar, output_notebook, show, hplot
2 import math
3 output_notebook()
4
5 counts = df.event.value_counts()
ImportError: No module named 'bokeh.charts'
Длины текстов (в символах)
Токенизация
Используем регулярные выражения, чтобы разбить тексты на слова
Самые частые слова
Закон Ципфа
Закон Хипса
Регулярные выражения подробнее
Классы символов:
[A-Z] – символы верхнего регистра (латиница)
[a-z] – символы нижнего регистра (латиница)
[А-Я] – символы верхнего регистра (кириллица)
[а-я] – символы нижнего регистра (кириллица)
[0-9] или \d – цифра
[^0-9] или \D – любой символ, кроме цифры
. – любой символ
Служебные символы:
\t – табуляция
\s – любой пробельный символ
\S – все символы, кроме пробельных
\n – перенос строки
^ – начало строки
$ – конец строки
__ – экранирование
Операторы:
? - предыдущий символ/группа может быть, а может не быть
+ - предыдущий символ/группа может повторяться 1 и более раз
* - предыдущий символ/группа может повторяться 0 и более раз
{n,m} - предыдущий символ/группа может повторяться от от n до m включительно
{n,} - предыдущий символ/группа в скобках может повторяться n и более раз
{,m} - предыдущий символ/группа может повторяться до m раз
{n} - предыдущий символ/группа повторяется n раз
Внутри групп не работают операторы ., +, *, их необходимо экранировать с помощью обратного слеша: \
Методы:
re.match(pattern, string) - найти подстроку pattern в начале строки string
re.search(pattern, string) - аналогичен методу match, но ищет не только в начале строки (но возвращает только первое вхождение!)
re.findall(pattern, string) - возвращает все вхождения pattern в string в виде списка
re.split(pattern, string, [maxsplit=0]) - разделяет строку string по шаблону pattern; параметр maxsplit отвечает за максимальное количество разбиений (если их существует несколько).
re.sub(pattern, string2, string1) - заменяет все вхождения pattern в string1 на srting2
re.compile(pattern) - создает объект для последующего поиска
Задание 1
Найдите в тексте все номера телефонов; текст лежит в файле 'task1.txt'. Обратите внимание на возможные форматы написания номеров.
Сегментация предложений
"?", "!" как правило однозначны. Проблемы возникают с ".".
Бинарный классификатор для сегментации предложений: для каждой точки "." определить, является ли она концом предложения или нет.
Задание 2
Посчитайте количество токенов и предложений в тексте из файла task2.txt. Сохраните список токенов в массив tokens.
Частотный анализ текста
Задание 3
Посчитайте, сколько слов в тексте task2 встречается больше одного раза.
Посчитайте количество слов, состоящих из 5 букв и более.
Морфологический анализ
Задачи морфологического анализа
Разбор слова — определение нормальной формы (леммы), основы (стема) и грамматических характеристик слова
Синтез слова — генерация слова по заданным грамматическим характеристикам
Морфологический процессор – инструмент морфологического анализа
Морфологический словарь
Морфологический анализатор
Лемматизация
У каждого слова есть лемма (нормальная форма):
кошке, кошку, кошкам, кошкой кошка
бежал, бежит, бегу бежать
белому, белым, белыми белый
Стемминг
Слова состоят из морфем: . Стемминг позволяет отбросить аффиксы. Чаще всего используется алгоритм Портера.
1-ый вид ошибки: белый, белка, белье бел
2-ой вид ошибки: трудность, трудный трудност, труд
3-ий вид ошибки: быстрый, быстрее быст, побыстрее побыст
Алгоритм Портера состоит из 5 циклов команд, на каждом цикле – операция удаления / замены суффикса. Возможны вероятностные расширения алгоритма.
Разбор слова
Задание 4
Найдите в списке персонажей романа "Война и мир" (task4.txt) все уникальные женские имена.
Первичная обработка текстов
Удаление стоп-слов
Синтаксический анализ
Грамматика зависимостей
Я купил кофе в большом магазине
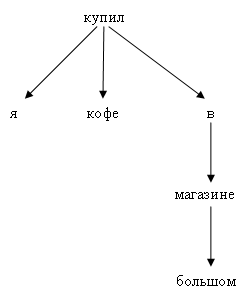
Все слова в предложении связаны отношением типа "хозяин-слуга", имеющим различные подтипы
Узел дерева – слово в предложении
Дуга дерева – отношение подчинения
SyntaxNet
SyntaxNet – архитектура синтаксического парсера. Доступны обученные модели для более чем 40 языков, в том числе, для русского.
D. Chen and C. D. Manning. A Fast and Accurate Dependency Parser using Neural Networks. EMNLP. 2014.
Тройки субьект-объект-глагол:
Задание 5
Измените код выше так, чтобы учитывались: 1. Однородные члены предложения * (парк, площадка), (Германия, Щвейцария) 2. Сложные сказуемые * (начнет продавать), (запретил провозить) 3. Непрямые объекты * (едет, Польшу), (спел, скандале)